This tests:
-
System design depth
-
Understanding of distributed systems
-
Trade-off navigation (CAP, consistency, latency)
-
Real-world edge case handling
Let’s go step by step and design Redis-like cache from first principles, not using cloud-managed services.
🚀 Goal: Build a Redis-like Distributed In-Memory Cache
🧾 1. Requirements Gathering (Clarify with interviewer)
🔹 Functional
-
Support GET, SET, DEL, TTL
-
Handle concurrent reads/writes
-
Cache keys across multiple nodes
-
Optional: Support pub/sub, data structures (hash, list)
🔹 Non-Functional
-
Low latency (<1ms typical)
-
High availability & fault tolerance
-
Scalable horizontally
-
Eventual or strong consistency
-
Memory-optimized with TTL eviction
Absolutely! Back-of-the-envelope estimations are crucial in system design interviews — they demonstrate your pragmatism, ability to roughly size a system, and to make sound trade-offs.
Let’s break it down for your Redis-like Distributed In-Memory Cache System:
🧠 Scenario:
Let’s say you're designing this for an AI/ML pipeline system, like Google's CMCS ML. It caches:
-
Intermediate model data
-
Feature store results
-
Token metadata
-
Configuration data
📌 Estimation Goals:
We’ll estimate for:
| What |
Example |
| 🔹 Number of keys |
e.g., 100 million |
| 🔹 Size per key |
e.g., average 1KB |
| 🔹 Total memory footprint |
GB / TB scale |
| 🔹 QPS (Queries Per Second) |
For read/write traffic |
| 🔹 Node count and distribution |
|
| 🔹 Network bandwidth |
|
| 🔹 TTL / Eviction rates |
|
⚙️ Step-by-Step Estimation
🔹 1. Number of Keys
Let’s say each ML workflow (pipeline) generates:
10k keys/workflow × 1M workflows/day = 10B keys/day
But not all stay in memory. We retain 10% for hot data in memory:
🔹 2. Average Key Size
Let’s assume:
Total = 1KB per key
📦 3. Total Memory Requirement
1B keys × 1KB = 1,000,000,000 KB = ~1 TB
So you’d need ~1 TB of RAM across your cluster
Let’s budget for 30% overhead (replication, GC, fragmentation):
➡️ Effective: ~1.3 TB RAM
🧵 4. QPS (Queries Per Second)
Assume:
10B reads/day ≈ 115,740 reads/sec
Writes: 1B/day ≈ 11,500 writes/sec
Target QPS:
-
Read QPS: 100K–150K
-
Write QPS: 10K–20K
🧑🤝🧑 5. Number of Nodes
If 1 machine supports:
-
64 GB usable memory
-
10K QPS (to be safe)
-
10 Gbps NIC
Then:
-
RAM: 1.3 TB / 64 GB ≈ 20 nodes
-
QPS: 150K / 10K = 15 nodes
Plan for ~25–30 nodes (for headroom and HA)
🔁 6. Replication Overhead
Assuming:
➡️ RAM required: ~2.6 TB
➡️ Bandwidth: double write traffic (~20K writes/sec * 1KB = ~20 MB/sec replication stream)
📶 7. Network Bandwidth
Let’s estimate:
📌 Each node should handle:
⏳ 8. Eviction Rate
Assuming TTL = 1 hour, and 1B keys:
Eviction algorithm must be efficient:
✅ Final Summary
| Metric |
Estimation |
| Total keys |
1 billion |
| Avg size per key |
1 KB |
| Total RAM (w/ overhead) |
~2.6 TB (with replication) |
| Nodes |
25–30 (for HA, QPS, memory headroom) |
| Read QPS |
~150K/sec |
| Write QPS |
~15–20K/sec |
| Eviction rate |
~250–300K/sec |
| Network per node |
~10 MB/s total (within 10Gbps budget) |
🎯 Bonus: What Google Might Ask
What would change if you needed to support multi-tenant isolation?
→ Talk about namespacing keys, quota control, per-tenant memory buckets.
What if a single user uploads a 1GB object?
→ Chunk large values or offload to Blob storage and cache pointer.
How would you reduce memory cost?
→ TTL tuning, compression (LZ4), lazy expiration.
🧱 2. High-Level Architecture
+------------------------+
| Client Applications |
+------------------------+
|
v
+------------------+
| Coordinator / |
| Cache Router | (Optional)
+------------------+
|
+------------------+------------------+
| |
+----------+ +-------------+
| Cache | <-- Gossip/Heartbeat --> | Cache |
| Node A | Protocol | Node B |
+----------+ +-------------+
| |
+------------+ +-------------+
| Memory DB | | Memory DB |
+------------+ +-------------+
🧠 3. Core Components
🔸 a. Data Storage (In-Memory)
-
Use hash maps in memory for key-value store
-
TTLs stored with each key (for expiry eviction)
-
Optionally support data types like list, hash, etc.
store = {
"foo": { value: "bar", expiry: 1681450500 },
...
}
🔸 b. Shard & Partition
This avoids rehashing all keys when nodes are added/removed
🔸 c. Cache Router / Coordinator
🔸 d. Replication
Node A (Master)
└── Replica A1
🔸 e. Eviction Strategy
-
Support TTL for automatic key expiry
-
Support LRU / LFU / random eviction when memory full
-
Track access counters for eviction ranking
🔸 f. Concurrency
🔁 4. Replication and Fault Tolerance
Gossip/Heartbeat
Failover
🧪 5. Optional Features
| Feature |
Description |
| Pub/Sub |
Add pub/sub channels per key prefix |
| Persistence |
Periodically write snapshots to disk (RDB), or append-only logs (AOF) |
| Backpressure |
Queue or reject new writes if memory full |
| Client Library |
SDKs to abstract hash ring + failover |
🔁 6. CAP Trade-off
| CAP Property |
Redis Default |
| Consistency |
Eventual (async replication) |
| Availability |
High (failover supported) |
| Partition Tolerance |
Yes |
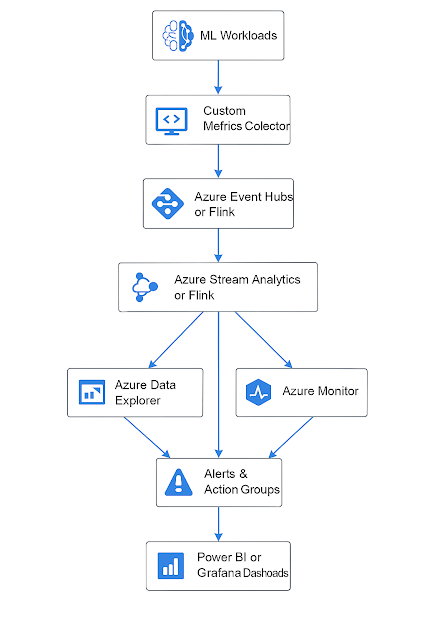
📊 Metrics to Expose
-
Hit/Miss rate
-
Memory usage
-
Eviction count
-
Node replication lag
-
Key distribution balance
🧠 Questions Google May Ask You During This Design
-
How would you handle hot keys (one key accessed by many nodes)?
-
How do you rebalance keys after node failure?
-
Would you support atomic operations (INCR, DECR)?
-
How do you prevent cache stampede (multiple clients recomputing a missing key)?
-
How do you handle large objects that exceed single node memory?
🛠️ Tech Stack (if you had
to build it)
|
Component
|
Tech
|
|
Cache server
|
C++ / Rust / Go (like Redis)
|
|
Hashing & comm
|
Consistent hashing + TCP sockets / gRPC
|
|
Replication
|
Raft or custom pub/sub protocol
|
|
Persistence
|
RocksDB / Flat file / Append logs
|
|
Observability
|
Prometheus + Grafana
|
Perfect — let’s walk through each of those Staff-level system design questions, and I’ll give you solid answers with reasoning, trade-offs, and implementation suggestions. You can use these to explain your decisions clearly in the interview.
🔥 1. How would you handle hot keys (one key accessed by many nodes)?
Problem:
✅ Solutions:
-
Key Replication (Read Replicas):
-
Replicate hot key across multiple nodes.
-
Client-side read load balancing (randomly pick from replicas).
-
Write goes to master → async to replicas.
-
Key Sharding (Virtual Keys):
-
Split key logically, e.g., "video:views" → video:views:1, ...:2
-
Clients randomly select a shard for read/write → reduce contention.
-
Aggregate during reads (costly but effective).
-
Request Deduplication & Caching at Edge:
-
Rate Limiting / Backpressure:
Interview Tip:
Emphasize dynamic detection of hot keys (via metrics), and adaptive replication or redirection.
💡 2. How do you rebalance keys after node failure?
Problem:
✅ Solutions:
-
Consistent Hashing + Virtual Nodes:
-
Auto-Failover & Reassignment:
-
Key Migration Tools:
-
Client-Side Awareness:
Interview Tip:
Talk about graceful degradation during rebalancing and minimizing downtime.
⚙️ 3. Would you support atomic operations (INCR, DECR)?
✅ Yes — atomic operations are essential in a caching layer (e.g., counters, rate limits, tokens).
Implementation:
-
Single-Threaded Execution Model:
-
Compare-And-Swap (CAS):
-
Locks (Optimistic/Pessimistic):
-
Use CRDTs (Advanced Option):
Interview Tip:
Highlight that simplicity, speed, and correctness are the priority. Lean toward single-threaded per-key operation for atomicity.
🧊 4. How do you prevent cache stampede (multiple clients recomputing a missing key)?
Problem:
✅ Solutions:
-
Lock/SingleFlight:
-
First client computes and sets value.
-
Others wait for value to be written (or reused from intermediate store).
-
Go has sync/singleflight, Redis can simulate with Lua locks.
-
Stale-While-Revalidate (SWR):
-
Request Coalescing at API Gateway:
-
Early Refresh Strategy:
Interview Tip:
Describe this as a read-heavy resilience pattern. Emphasize proactive + reactive strategies.
📦 5. How do you handle large objects that exceed single node memory?
Problem:
✅ Solutions:
-
Key Chunking (Manual Sharding):
-
Split large value into multiple keys (file:1, file:2, file:3).
-
Store each chunk on different nodes.
-
Reassemble during read.
-
Redirect to Object Store:
-
Use a Tiered Cache:
-
Compression:
Interview Tip:
Discuss threshold-based offloading and trade-off between latency vs. capacity.